
In the second part of my Codecademy project I was assigned to build an Naive-Bayes algorithm to tell whether a tweet someone wrote originated from either NYC, London, or Paris. Not gonna lie that sounds hella cool, but before I carry on what is a Naive-Bayes algorithm?
NBA is a popular classification machine learning algorithm that classifies data based upon conditional probability values computation. Basically it tells me the probability that the inputted data is associated with another piece of data, by comparing them to vectors. Vectors are a way to format data by numbering the frequency a word appears. For example “I love New York City, New York!” The words “I”, “City” and “love” will be assigned the number 1 as they appeared only once. “New” and “York” will be assigned the number 2. I’ll feed NBA with thousands of tweets from NYC, London, and Paris to make it’s own vectors to learn from. I think it’s safe to assume people from different regions probably use the same style of speaking and words to communicate, and if we had a big enough vector-pool to learn from our algorithm could begin to notice patterns.
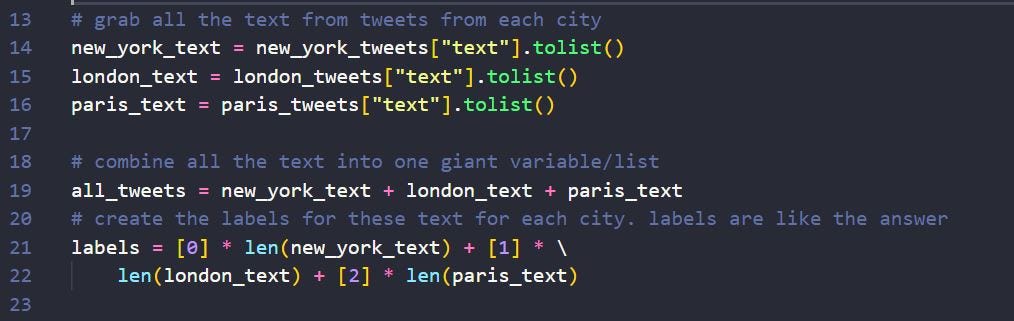
Codecademy was able to provide me with three large twitter files from NYC, London, and Paris. These files contained too much information, and all I’m interested in is the actual text of each tweet. I made three variables for each city and propagated a list using the .tolist() function. After that I combined all three lists into one, and created a label variable to identify which city corresponded to each tweet. Since I had three cities the labels were either 0 for NYC, 1 for London, or 2 for Paris.
After this I needed to train and test my data using the sklearn.model_selection’s train_test_split() function. This function takes my data (all_tweets) and the labels (the answers) and returns to me the training data and training labels along with the testing data and testing labels. The function comes up with it’s own test so I can compare it with the actual inputs. Neat!

Now I need my vectors I told you about earlier. To do this I will have to use the sklearn.feature_extraction.text module to import the CountVectorizer function to do the heavy lifting for me. The CountVectorizer has a .fit() function that teaches the counter our vocabulary. This is where I can pass my train_data variable into. From there I can transform my train_data and test_data into the count vectors.

Now that I have all my vectors I can finally use the NBA. In python it’s found in the sklearn.naive_bayes module as MultinomialNB. I’ll pass the train_counts and test_counts into it after I make the classifier object, and train the classifier using the .fit() function. After all that I can use the .predict() function to see how well the NBA made my predictions. To check the accuracy I used the accuracy_score() function from sklearn.metrics module. The algorithm was succeeding at a 67% rate! For fun I added my own tweet and “Come on over for a cupa!” was categorized as a tweet from London. “These rats are getting out of control.” returned as a tweet from NYC. Sounds right to me.

Another great way to evaluate NBA accuracy is to use the confusion_matrix which will return a matrix of where it made its guess.

The first row is for NYC, and within that row it shows where it placed it’s predictions. 541 tweets to NYC, 404 to London, and 28 to Paris. The second row for London, and the third for Paris. It looks like NYC and London in the first row where closer together than the other two cities has in their own rows. Why do you think this is? Parisian tweets were probably easier to differentiate due to the language, but why was the algorithm so much more definitive on a London tweet than it was with a New Yorker’s tweet?