
In my latest codecademy project I used a survey from FiveThirtyEight on What Do Men Think It Means To Be A Man? The whole article is worth a read, and I think these sort of surveys are great for K-Means cluster analysis. After reviewing the survey I decided to look at one questions in particular:
How often would you say you do each of the following?
- Ask a friend for professional advice.
- Ask a friend for personal advice.
- Express physical affection to male friends, like hugging, rubbing shoulders.
- Cry
- Get in a physical fight with another person.
- Have sexual relations with women, including anything from kissing to sex.
- Have sexual relations with men, including anything from kissing to sex.
- Watch sports of any kind.
- Work out.
- See a therapist.
- Feel lonely or isolated.
Each question could be answered with the following: Often, Sometimes, Rarely, Never but open to it, Never and not open to it.
You can see how many ways this one question in the survey could be broken down. So my first step was to location this question within it’s sub-questions in the .csv file, and from there map over the answers and change them from a string to a numbered value using the .map() function.

Before I get to the KMeans model lets just plot two questions and see what I get.

Here I plotted “asking a friend for professional advice”, and “asking a friend for personal advice”. You can notice a few things from it, like how telling it is that both these questions are at lowly a 4 (often). It would make sense however if one was low than the you’d assume the other would be too. If someone isn’t asking for professional advice they’re probably not asking for personal advice either.
Moving to the next step it’s time to start building our KMeans cluster which can be imported from sklearn.cluster module. I’ll first create a variable grabbing only the columns associated with question 7 and the subset of questions I want (Questions: 1, 2, 3, 4, 5, 8, 9). Codecademy wants me to analyze question 1, 2, 3, 4 are they’re the most non-masculine attributes to admit to, and 5, 8, 9 are the most masculine. Lastly I’ll want to use the .dropna() function to remove all columns without values filled in for -answers that were left blank by the surveyed.

Now that I have my KMeans set up let me find how many clusters I have using the .cluster_centers_ on my classifier, and the .labels_ to see who falls into which cluster.
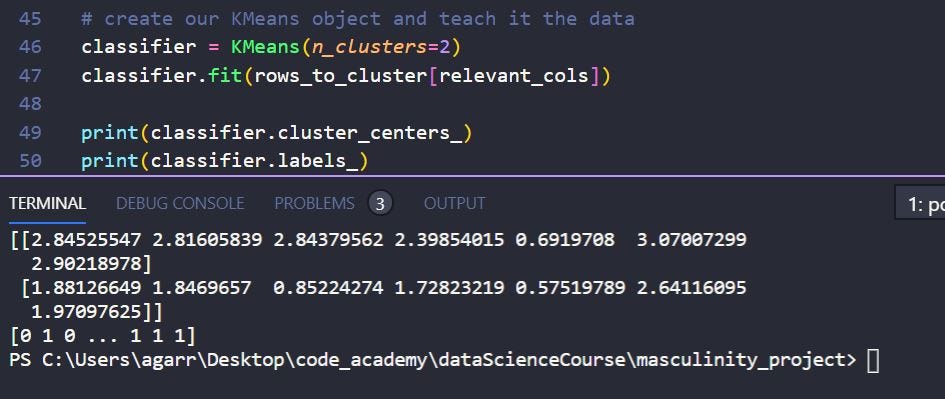
I can see I have two clusters and within the range each question falls into. It’s interesting. I believed that the first four questions and the last three would show up significantly in this cluster among themselves, but it doesn’t seem to weight-out that way. Instead the first cluster just shows that its a group that does more things along all the questions, and the second cluster does less of everything.
What I want to do next is to group these labels of one’s and zero’s into their own list, so I can study them more closely. I’ll use a for-loop for this and populate two empty lists.

Alright now that I have those separated I can crate a new data-frame of each, and then explore different categories of each group. Like age, and education and see if there is any relevance.

I decided to check out differences in education and age. There are some noticeable changes and the starkest being among high-school graduates. Ages also showed some significant differences, but the youngest age range 18–34 being the most similar. KMeans is a great resource to investigate surveys such as these. I’ve already spent the whole day looking at it. Thankful they wrote a whole article on it too! But it’s evident why KMeans has been around for over five decades.